RSS content encoding in Astro
I was setting up the RSS feed for my Astro blog, and was happy to learn that
there’s an official @astrojs/rss
package! With
the help of that and their RSS setup
instructions,
setting up the feed was simple enough. But being ever the fastidious developer,
I wanted to make sure everything was prim and proper and opened up the feed in
my browser. I was surprised to see the raw HTML content of the post, not wrapped
within a <![CDATA[ ... ]]> section as I expected. It looked something like:
<content:encoded>
<p>This is the fake <abbr>HTML</abbr> text of a post.</p>
</content:encoded>This didn’t seem right. I double-checked some of the feeds I follow and sure
enough, they had a CDATA wrapping their content. I figured I’d better add it,
so I just chucked it in like this, despite the gnawing feeling that there had to
be a more idiomatic way:
const items = posts.map((post) => ({
...post.data,
description: `<![CDATA[${post.data.description}]]>`,
content: `<![CDATA[${sanitizeHtml(parser.render(post.body))}]]>`,
link: `/posts/${post.slug}/`,
}));Checking my feed in the browser again, everything looked correct to my eyes! Shipped it off to production, and loaded my feed into Feedbin to have a look at how the posts looked in an actual RSS reader. Everything looked perfect, until I got to the end of the feed and saw:
]]>
A CDATA end marker was just sitting there, chilling at the bottom of the post. At this point, I really should have checked my assumptions and thought things through again. But instead I started searching the web - was this a bug in Astro? In Feedbin, even? I combed through the other feeds I was comparing mine to, in order to figure out if they were doing something I was missing in mine.
A few failed fixes and grey hairs later, upon looking at my feed in the browser for the hundredth time, I had a sinking feeling in my gut as I realised what I was looking at was perhaps not the raw source as I thought:
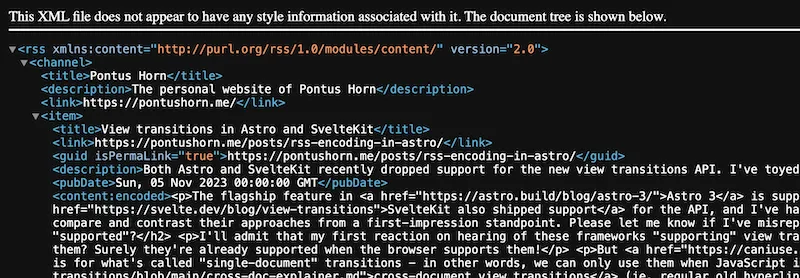
The text above it and the foldable regions should probably have given it away
sooner. Whoops! I added view-source: in front of the feed URL, and lo and
behold - the post HTML was already encoded. So was my CDATA wrapper, which
explains the lost little end marker (I guess the HTML parser ate the start tag,
or something of that nature). But as long as entities are properly encoded,
which they seemed to be, the CDATA wrapper should be superfluous.
In summation, there was no bug, and the whole problem was imagined from the start. Is there a moral to this story? Not sure. I can always use a good reminder to check my assumptions, though, and this was as good as any.